Types de fichiers PDF
Les documents PDF peuvent être classés en trois types différents, selon la façon dont le fichier a été créé. La manière dont le fichier a été créé définit aussi si le contenu du fichier PDF (texte, images, tableaux) peut être accessible ou s’il est « scellé » dans l’image de la page.
PDF créés numériquement ou PDF « normaux »
Ces types de PDF sont créés directement à partir d’autres applications comme les logiciels de traitement de texte, logiciels de calcul, outils de conception graphique, etc. Ce type de documents PDF ne comporte que du texte et des images, sans couche image et est interrogeable, sauf lorsque le document comporte du texte sous forme de graphique vectoriel ou de pixels d’image.
Les caractères de texte et les méta-informations ont un caractère numérique correspondant. Le logiciel ABBYY FineReader PDF vous permet d'effectuer facilement des recherches dans les fichiers PDF, de sélectionner, copier ou même éditer des contenus, de la même manière qu'avec d'autres programmes de traitement de texte tels que Microsoft® Word. Il est possible de changer la taille des images contenues dans les documents PDF numériques, de les déplacer ou encore de les supprimer.
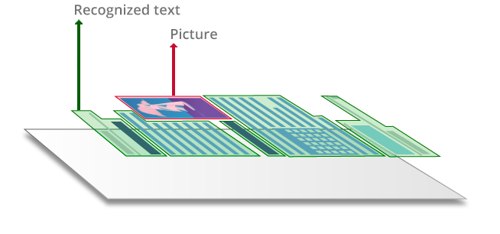
PDF « image seulement » ou PDF scannés
Lors de la numérisation de documents papier sur les MFP et scanners de bureau, ou lors de la conversion d’une image de la caméra, jpg, tiff ou capture d’écran dans un PDF, le contenu est « scellé » dans une image instantanée.
Ces documents PDF « image seulement » contiennent seulement les images photographiées ou numérisés de pages, sans une couche de texte. Par conséquent, les fichiers PDF « image seulement » ne sont pas interrogeables, et leur texte ne peuvent généralement pas être modifiés ou marqués. Un PDF « image seulement » peut être devenir interrogeable grâce à l’application OCR avec laquelle un calque texte est ajouté, normalement sous l’image de la page.
PDF interrogeables
Pendant le processus de reconnaissance de texte, les caractères et la structure du document sont analysés et «lus». Une couche texte est ajoutée à la couche image, qui est généralement placée au-dessous. Ces fichiers PDF sont presque indiscernables des documents originaux et sont entièrement interrogeables. Le texte dans les documents PDF interrogeables peut être sélectionné, copié et balisé.
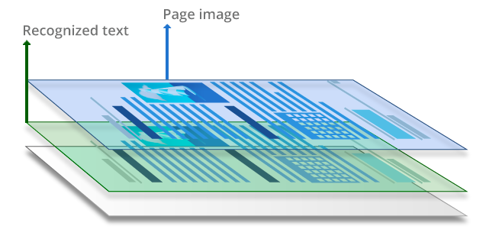
La technologie de reconnaissance de texte peut être appliquée de différentes manières au cours du processus de conversion de documents, chacune nécessitant différents niveaux de participation de l’utilisateur. Elle peut être :
- intégrée dans le dispositif de numérisation : la conversion passe plus ou moins inaperçue auprès de l’utilisateur
- via OCR de bureau, comme ABBYY FineReader PDF, via une application mobile ou un service basé sur le Web
- dans un outil PDF, comme ABBYY FineReader PDF, lors de la numérisation ou l’ouverture d’un document PDF : le processus OCR démarre automatiquement ou peut être démarré par l’utilisateur
- en utilisant une solution OCR basée sur le serveur, comme ABBYY FineReader Server : conversion automatisée des volumes plus élevés dans les grandes organisations ou des projets d’archivage numérique
- ou comme un « service » dans le Cloud.