Arten von PDFs
PDF-Dokumente können in drei Kategorien unterteilt werden, je nachdem wie eine Datei ursprünglich erstellt wurde. Dies bestimmt auch, ob auf ihren Inhalt (Text, Bilder, Tabellen) zugegriffen werden kann, oder ob dieser in einem Bild der Dokumentenseite gebunden, also „eingeschlossen“, ist.
„Normales” oder digital erstelltes PDF
Digital erstellte PDFs, auch bekannt als „normale“ PDFs, werden direkt aus Softwareanwendungen wie Microsoft® Word, Excel® oder via der Druckfunktionen (Virtueller Druckertreiber) einer Anwendung erstellt. Sie bestehen aus Text und Bild.
Hier haben sowohl die Textzeichen als auch die Meta-Informationen eine digitale Zeichenentsprechung. Mithilfe von ABBYY FineReader PDF sind diese PDF-Dateien leicht durchsuchbar, Inhalte können ausgewählt, kopiert oder gar editiert werden, ähnlich wie man es von anderen Textverarbeitungsprogrammen wie Microsoft® Word gewohnt ist. Bilder in digital erstellten PDF-Dokumenten können in der Größe geändert, bewegt oder gelöscht werden.
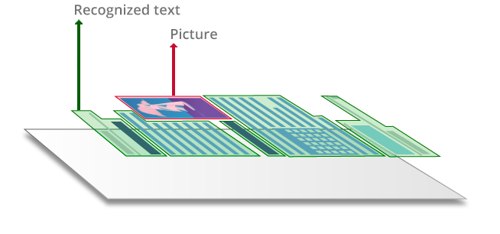
Gescanntes PDF (oder „Bild-PDF”)
Beim Scannen von Papierdokumenten auf MFP-Geräten oder Büroscannern, oder beim Umwandeln von Kamera-Fotos, JPGs, TIFs oder Screenshots in PDF-Dateien entstehen “Bild-PDFs”, bei denen der gesamte Inhalt in einem schnappschuss-ähnlichen Bild „eingeschlossen” ist.
Solche gescannte PDFs enthalten Scans oder Fotos von Seiten ohne eine darunterliegende Textebene. Folglich sind diese PDFs nicht durchsuchbar, Text kann nicht markiert oder verändert werden. Ein gescanntes PDF kann mit OCR durchsuchbar gemacht werden, wobei eine Textebene hinzugefügt wird, üblicherweise unter dem Seitenbild. Sie kann durch eine PDF-Technologie mit integriertem leistungsstarken OCR auch bearbeitbar gemacht werden – wie dies zum Beispiel beim FineReader PDF geschieht, wo Sie gescannte PDF direkt bearbeiten können, ohne diese in eine andere Datei oder ein anderes Format konvertieren zu müssen.
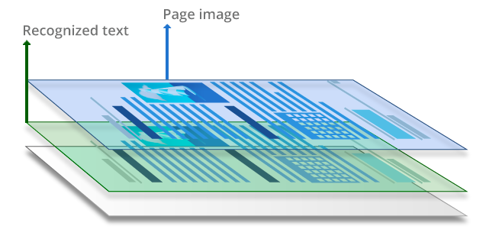
Durchsuchbares PDF
Durchsuchbare PDFs sind in der Regel das Ergebnis der Anwendung von OCR (Optical Character Recognition) auf gescannte PDFs oder andere bildbasierte Dokumente. Während dem Texterkennungsprozess werden Dokumentenstruktur und Textzeichen analysiert und “gelesen”. Eine Ebene mit dem erkannten Text wird dem Seitenbild hinzugefügt – in der Regel unter der Bildebene. Diese PDFs sind optisch kaum von den Originaldokumenten zu unterscheiden, jedoch voll durchsuchbar. Texte können markiert, ausgewählt und bearbeitet werden.
Während der Dokumentenumwandlung kann OCR/Texterkennung auf unterschiedliche Weise auf PDFs angewendet werden – mit unterschiedlichem Beteiligungsbedarf seitens des Anwenders:
- Integriert in den Scanner: die Umwandlung läuft im Hintergrund, mehr oder weniger unbemerkt vom Nutzer ab
- Via Desktop-Software, via einer Mobile App oder als webbasierter Service
- Innerhalb einer PDF-Software, wie ABBYY FineReader PDF, beim Scannen oder beim Öffnen von PDF-Dokumenten: der OCR-Prozess startet automatisch oder kann durch den Benutzer initiiert werden
- Einsatz einer serverbasierten Dokumentenumwandlungslösung, wie ABBYY FineReader Server: automatische Umwandlung von umfangreichen Dokumentenvolumen in größeren Organisationen oder Projekten zur digitalen Archivierung
- Als “Service” in der Cloud.