Types of PDFs
PDF documents can be categorized in three different types, depending on the way the file originated. How it was originally created also defines whether the content of the PDF (text, images, tables) can be accessed or whether it is “locked” in an image of the page.
“True” or digitally created PDFs
Digitally created PDFs, also known as "true" PDFs, are created using software such as Microsoft® Word®, Excel® or via the “print” function within a software application (virtual printer). They consist of text and images.
Both the characters in the text and the meta-information have an electronic character designation. With ABBYY FineReader 15 you can easily search through these PDFs and select, edit or delete text similar to how you would do that in other editable formats such as Microsoft® Word®. The images in digitally created documents can be resized, moved, or deleted.
“Image-only” or scanned PDFs
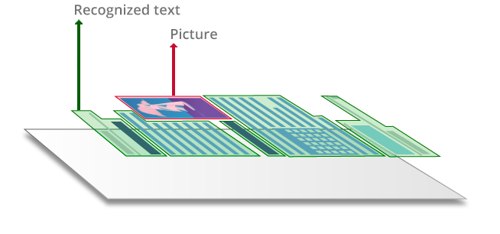
When scanning hard copy documents on MFPs and office scanners, or when converting a camera image, jpg, tiff or screenshot into a PDF, the content is “locked” in a snapshot-like image.
Such image-only PDF documents contain just the scanned/photographed images of pages, without an underlying text layer. Consequently, image-only PDF files are not searchable, and their text usually cannot be modified or marked up. An “image-only” PDF can be made searchable by applying OCR with which a text layer is added, normally under the page image.
Searchable PDFs
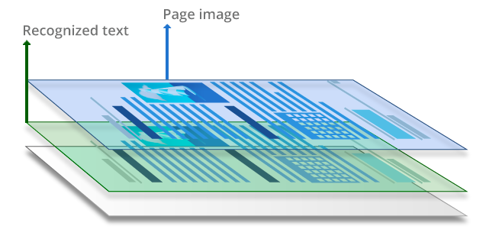
Searchable PDFs usually result through the application of OCR (Optical Character Recognition) to scanned PDFs or other image-based documents. During the text recognition process, characters and the document structure are analyzed and “read”. A text layer is added to the image layer, usually placed underneath. Such PDF files are almost indistinguishable from the original documents and are fully searchable. Text in searchable PDF documents can be selected, copied, and marked up.
Text recognition technology can be applied in different ways during the document conversion process, each requiring different levels of involvement by the user. It can be:
- Integrated into the scanning device: conversion happens more or less unnoticed by the user.
- Via desktop OCR software, a mobile app or a web-based service.
- Within a PDF tool, scanning or opening a PDF document: the OCR process will start automatically or can be triggered by the user.
- Using a server-based OCR solution, such as ABBYY FineReader Server: automated conversion of higher volumes in large organizations or digital archiving projects.
- Or as a “service” in the cloud.