Tipi di PDF
I documenti PDF possono essere classificati in tre tipologie diverse in base al modo in cui è stato originato il file. Il modo in cui è stato creato il file stabilisce anche se è possibile accedere al contenuto del PDF (testo, immagini, tabelle) o se questo è invece "sigillato" in un'immagine della pagina.
“True PDF” (normali) o creati digitalmente
I PDF creati digitalmente, conosciuti anche come "true PDF", sono creati utilizzando software quali Microsoft® Word, Excel® o tramite la funzione di "stampa" all'interno di un'applicazione software (stampante virtuale) e sono costituiti da testo e immagini.
Sia i caratteri del testo che le meta-informazioni presentano una designazione elettronica del carattere. Con ABBYY FineReader PDF è possibile eseguire facilmente delle ricerche all'interno di questi PDF nonché selezionare, modificare o eliminare testo in modo simile a quello di altri formati modificabili quali Microsoft® Word. Le immagini nei documenti creati digitalmente possono essere ridimensionate, spostate o eliminate.
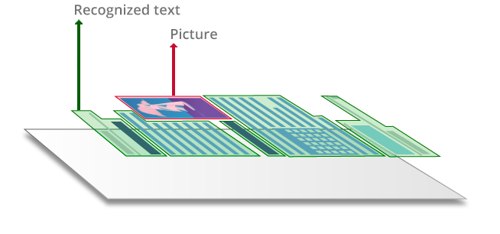
PDF "di sola immagine" o scannerizzati
Quando si scannerizzano documenti cartacei su dispositivi MFP o scanner, oppure si converte una fotografia digitale, un jpg, un tiff o uno screenshot in un PDF, il contenuto viene "sigillato" in un'immagine simile a un foto.
Questi documenti PDF di sola immagine contengono unicamente le immagini scannerizzate/fotografate delle pagine senza un livello di testo sottostante. Pertanto i PDF di sola immagine non sono ricercabili e il relativo testo non può essere modificato né contrassegnato. È possibile rendere ricercabile un PDF "di sola immagine" applicando la tecnologia OCR con la quale viene aggiunto un livello di testo, normalmente sotto l'immagine della pagina.
PDF ricercabili
I PDF ricercabili sono normalmente creati eseguendo l'OCR (riconoscimento ottico dei caratteri) su PDF scannerizzati o su altri documenti basati su immagini. Durante il processo di riconoscimento del testo, i caratteri e la struttura del documento vengono analizzati e "letti". Viene aggiunto un livello di testo al livello dell'immagine, solitamente posizionato al di sotto di essa. Questi file PDF risultano quasi del tutto indistinguibili dai documenti originali e sono completamente ricercabili. All'interno di essi il testo può essere selezionato, copiato e contrassegnato.
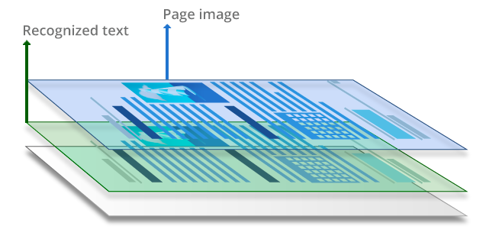
La tecnologia di riconoscimento del testo può essere applicata in modi diversi durante il processo di conversione del documento, ognuno dei quali prevede livelli diversi di coinvolgimento dell'utente. Il riconoscimento può avvenire secondo le modalità elencate di seguito.
- Integrato nel dispositivo di scansione: la conversione avviene in background e passa pressoché inosservata da parte dell'utente.
- Tramite software OCR su desktop, come ABBYY FineReader PDF, tramite applicazione su dispositivo mobile o servizio basato sul web
- Utilizzando un tool PDF, come ABBYY FineReader PDF, durante la scansione o all'apertura di un documento PDF: il processo OCR inizia automaticamente o può essere attivato dall'utente.
- Utilizzando una soluzione OCR basata su server, come ABBYY FineReader Server: per la conversione automatizzata di cospicui volumi all'interno di grandi organizzazioni o nell'ambito di progetti di archiviazione digitale.
- Come un "servizio" nel Cloud.