Tipos de PDF
Los documentos PDF se pueden clasificar en tres tipos diferentes en función de cómo se hayan generado. Además, su creación original define si el contenido del PDF (texto, imágenes, tablas) resulta accesible o si está «bloqueado» como una imagen de la página.
PDF «verdaderos» o creados digitalmente
Los archivos PDF creados digitalmente, también conocidos como «verdaderos» PDF, se generan con software como Microsoft® Word o Excel®, o mediante la función de «imprimir» en una aplicación de software (impresora virtual). Contienen texto e imágenes.
Tanto los caracteres del texto como la metainformación tienen una designación de caracteres electrónica. Con ABBYY FineReader PDF 15 podrá buscar fácilmente en estos PDF y seleccionar, editar o borrar texto de forma similar a como se hace en otros formatos editables, como Microsoft® Word. Además, las imágenes de los documentos creados digitalmente pueden moverse, cambiarse de tamaño o borrarse.
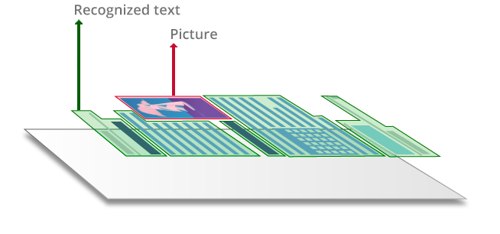
PDF de «solo imagen» o escaneados
Cuando se escanean documentos en papel con MFP y escáneres de oficina o se convierte una imagen jpg, tiff, de una cámara o una captura de pantalla a un PDF, el contenido está «bloqueado» en una imagen similar a una captura.
Este tipo de documentos PDF de solo imagen solo contienen las imágenes escaneadas o fotografiadas de páginas, pero sin una capa de texto subyacente. Por consiguiente, en los archivos PDF de solo imagen no pueden realizarse búsquedas y su texto no suele poder modificarse ni marcarse. En un PDF «de solo imagen» se pueden realizar búsquedas aplicando la tecnología OCR, con la que se añade una capa de texto, normalmente bajo la imagen de la página.
PDF con capacidad de búsqueda
Los archivos PDF con capacidad de búsqueda suelen conseguirse aplicando OCR (reconocimiento óptico de caracteres) a PDF escaneados u otros documentos basados en imagen. Durante el proceso de reconocimiento del texto se analizan y «leen» los caracteres y la estructura del texto. Después se incorpora una capa de texto a la capa de imagen, normalmente debajo. Este tipo de archivos PDF son prácticamente imposibles de distinguir de los documentos originales y permiten cualquier búsqueda. El texto de los documentos PDF con función de búsqueda puede seleccionarse, copiarse y marcarse.
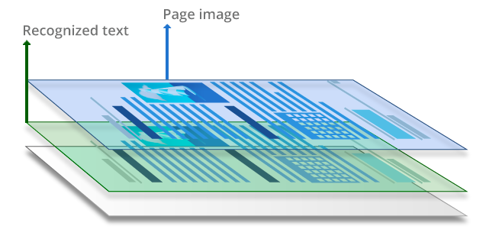
La tecnología de reconocimiento de texto puede aplicarse de diferentes formas durante el proceso de conversión de documentos, aunque cada forma requiere distintos niveles de participación por parte del usuario. Puede:
- Estar integrada en el dispositivo de escaneado: el usuario prácticamente no advierte que la conversión se está produciendo.
- Encontrarse en el software OCR de escritorio, una aplicación móvil o un servicio basado en web.
- Incluirse en una herramienta PDF: al escanear o abrir el documento PDF, el proceso de OCR se iniciará automáticamente o puede ser activado por el usuario.
- Usarse con una solución OCR basada en servidor, como ABBYY FineReader Server: así se convierten automáticamente grandes volúmenes en organizaciones de gran tamaño o proyectos de archivado digitales.
- O presentarse como un «servicio» en la nube.