Among all the variety of different existing variants of PDF, PDF/UA is definitely the one that shall become the most widespread. In a digital era, the Web became the major way to get around with many aspects of life, and people must do more and more interactions digitally. Such entities as state authorities, suppliers of services, banks, etc., publish an increasing number of documents on their websites. When people deal with them, more and more of self-service, self-engagement is expected, which means all the people shall be equally able to use those documents effectively. But worldwide there are an estimated 253 million people with vision impairment; and from 3 to 7 percent suffer from reading disorder (dyslexia). Therefore, the documents must be provided in a form that allows those people to access the information on their own. And that’s exactly what PDF/UA is about: providing all people equal accessibility to information in documents by using just one universal format.
“UA” stands for “Universal Accessibility”, and PDF/UA is a specification that defines how to make a PDF document readable by assistive technologies (special software or even devices) so that a computer can read the content of such document aloud to anyone who depends on these technologies. As PDF documents became common in our lives, and especially in such spheres as public services, banking, utility, employment, medical and many other types of services, ensuring equal and easy accessibility to them is crucial.
A PDF/UA document has a correctly defined and properly described logical structure. Using this structure description, assistive technology will know and will be able to tell what is the heading of the document, in which order to read the document’s paragraphs and text columns; what are the lists, where are the pictures and what they depict, skip reading repetitive headers and footers with page numbering, and so on.
The structure description is made using tags. Tags can be thoroughly defined when a PDF document is created, but let’s be realistic: even now this is not a common practice, not to mention PDF documents created 10 or 15 years ago. But there’s even more: about 1/3 of all PDFs are scanned PDFs, which means they have zero accessibility by default and no defined and described structure.
The power of PDF is that any of those non-accessible PDF documents can be converted into PDF/UA-compliant ones; the drawback is that it is an enormous task to be done manually. And that is when such PDF solutions as ABBYY FineReader come to help. FineReader can undertake a majority of the job by analyzing and retrieving the logical structure of any PDF document, even a scanned one, and adding the corresponding tags to embed a description of the structure in it. The latest improvements in the technology allow FineReader to do the tagging much more precisely, which allows for compliance with the PDF/UA standard. Of course, a PDF/UA document made by FineReader also complies to the standard in terms of defining the document’s metadata, heading, language(s), and so on. A PDF/UA document created with FineReader can be validated for compliance using a third-party validator, such as PAC3.
How to create PDF/UA documents with FineReader
ABBYY FineReader can both convert existing PDF documents of any type into PDF/UA ones, and create PDF/UA documents from files in other formats, such as DOCX, XLSX, PPTX, RTF, image files, and others. This is possible thanks to ABBYY OCR technology, which can analyze any document structure regardless of its format. To make sure the resulting PDF is universally accessible one, you just need to check the corresponding setting in the options:
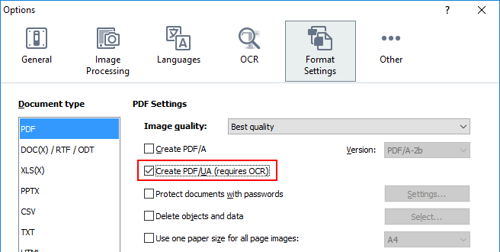
Notice that you can easily make the document both PDF/UA and PDF/A compliant at the same time:

And it is not magic. It is power and versatility of PDF and intelligence of ABBYY FineReader, which allow combining two sets of requirements so that the result meets them both.
Learn also about many other features that FineReader can offer.


