Digital Archiving enables e-discovery, litigation support and regulatory compliance and facilitates data analytics. Read more about how to preserve documents from paper and digital input channels as accessible and searchable PDF/A assets with FineReader Server.
To answer the question in the title, we should first understand what archiving is. Many people confuse it with back-up, so let’s go into details to differentiate them.
A backup is a snapshot of data at a given point of time, created to restore data in case of damage or loss.
An archive is a copy of all relevant information for long-term preservation and reference purposes, the original is often deleted after an archive is made.
The following table shows the main differences:
| Backup | Archive | |
| Period | Short-term retention Retained for as long as data is in active use |
Long-term retention Retained for required period or indefinitely |
| Content modification |
Easy Duplicate copies are periodically overwritten |
Difficult Data cannot be altered or deleted |
| Type of content |
Unindexed raw content | Indexed, searchable, and accessible |
Table 1: Backup vs Archive
While both backup and archive are important best practices, they are not interchangeable.
In addition to paper documents, here are the main types of electronic content that organizations archive, according to Osterman Research, Inc. (percentage of organizations archiving this content):
- Corporate email (89%)
- Users' files (53%)
- Content from Microsoft SharePoint or similar collaboration tools (26%)
- Content from company-managed file sync-and-share tools, such as Dropbox (19%)
- Other (16%)
As you see, email systems are in the lead for archiving and are usually a starting point. This isn’t surprising, because of the high prevalence of email and the wide variety of content it contains.
There are many reasons why organizations may need to digitally archive their documents. Let’s look at the main drivers and benefits.
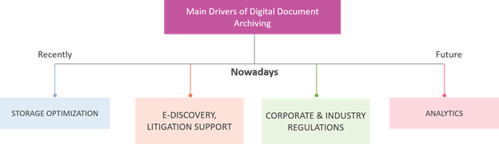
Picture 1: Main drivers of digital document archiving
Previously, the main reason for archiving was storage optimization, with the main purpose of preserving corporate memory for future possible needs (which sometimes might never arise). The other goal was to reduce repository size, but given the recent reduction of storage costs, this problem is probably a thing of the past. Other storage optimization benefits — like content migration support and employee productivity — are still very important today.
Currently the main drivers for archiving are litigation support, e-discovery, and corporate and industry regulations.
Archiving offers the following benefits for organizations that face trials:
- Simplification and acceleration of finding and producing specific records
- Feeding e-discovery platforms
- Early case assessment
- Legal holds
Different corporate and industry regulations compel organizations to retain and be able to produce a variety of business documents. Organizations around the world implement records management policies to satisfy these needs. Here are a few examples of different regulations with record-keeping requirements:
- HIPPA (USA, healthcare and health insurance industries)
- FINRA (USA, financial industry)
- FERC (USA, energy industry)
- FDA (USA, food and drug industries)
- The Companies Act 2006, UK and Sec. 257 German Commercial Code (general company records)
- CNIL recommendation n°2005-002 (France, medical and safety records)
Archiving used to be an expense of doing business, but now we see that it helps to reduce costs of doing business by
- Reducing staff time searching for necessary records
- Helping to avoid fines for not being compliant with regulations
- Helping to win trials
Based on current trends, tomorrow's main driver for archiving will be analytics. Feeding analytics and AI platforms, storage and file analysis, extracting insights from customer or employee communications, and proactive detection of internal issues and anomalies are only a few visible benefits of implementing information archiving solutions soon.
Speaking of long-term preservation of electronic documents, the main format used for this is PDF/A — an ISO-standardized version of the Portable Document Format (PDF) designed for use in archiving. This version differs from PDF by prohibiting features unsuitable for long-term archiving, such as font linking and encryption. All information such as content, colors, and fonts must be embedded in the file.
A solution from PDF Association member ABBYY — FineReader Server — facilitates compliance with government and corporate regulations by automatically converting large volumes of paper and digital documents into accessible and searchable PDF/A files. The server-based product receives document images from storage folders, multifunction printers, scanners, or e-mails and uses optical character recognition (OCR) technology to automatically convert them into compressed, searchable digital formats. If needed, the user and the system can add metadata to the document, and the user can manually correct text information. The service can run around the clock or process documents in batches on a scheduled basis to optimize use of hardware resources. The resulting digitized files can be saved to any number of storage areas and/or delivered to other applications.


