The new Release 3 of ABBYY FineReader PDF for Windows is relevant for almost every user as this update has something new that makes working with documents easier, faster, more efficient, more comfortable, and ultimately more satisfying.
Release 3 of FineReader PDF features updates in each of the four core parts of FineReader PDF: PDF Editor, OCR Editor, Compare Documents, and Hot Folder*. Read further to learn the details – off we go!
* Compare Documents and Hot Folder are only available in the more advanced FineReader PDF Corporate.
Editing and managing PDFs: New tools, improved settings control, and tackling “difficult” PDFs
Detect and delete blank pages
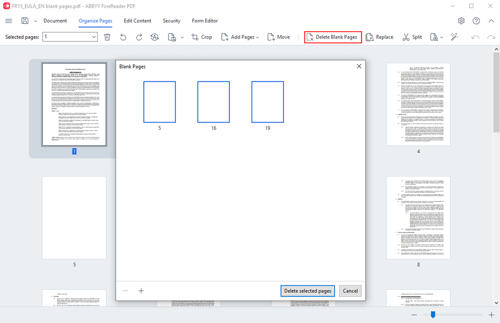
Some PDFs contain empty pages. Sometimes it’s a mistake of the document creator, but often they are there intentionally. When reusing such PDFs though, in many cases these pages are not needed and must be removed.
Now, FineReader PDF has a new “Delete Blank Pages” tool for that—it finds all empty pages in a PDF document for you to delete them in one click. But before deleting, the tool displays a preview of all found blank pages for you to review, and you can select the pages to delete and which to keep.
In PDF Editor, you can find the Delete Blank Pages button in the toolbar in Organize Pages view, and the corresponding command in the main menu. It’s also available with a keyboard shortcut Ctrl+Alt+Backspace.
Select multiple pages with a frame in Organize Pages
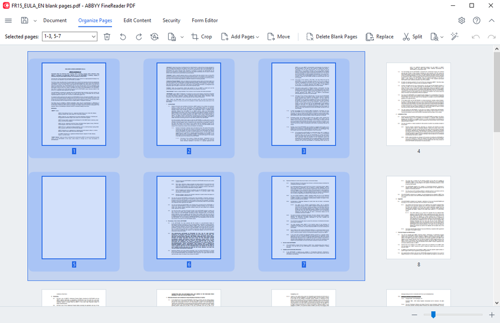
With the latest major release of FineReader PDF 16 in September 2022, Organize Pages view became a significant addition to the tool set of the software that streamlined PDF page manipulation processes and tasks, and introduced significant improvements to some of the included tools.
With the current Release 3, Organize Pages has a new feature. Now it is possible to select pages that you want to move, rotate, delete, extract from a PDF, etc., by dragging a frame over the thumbnails of pages with a mouse. This intuitive experience for every Windows user is a convenient way of selecting pages that adds efficiency when handling PDF documents.
Get better access to content in PDFs with incorrect text encoding
Not all digitally created PDFs are the same, nor easy to handle. To your eyes, they all may seem good, but you’d be surprised how many of them are created with text encoding butchered inside the PDF, sometimes even with a good purpose in mind. A common effect of such PDFs is that while you can read the document from the screen, you can’t select or copy any text from it, and you cannot edit those PDFs. To help you with that, GlyphRecovery technology was applied to PDF Editor in Release 3.
GlyphRecovery reconstructs encoding of characters in PDFs with incorrect text encoding on-the-fly, so you can edit such PDF documents and copy texts directly from them. GlyphRecovery is not perfect, though. It increases average accuracy of text extraction from PDFs with incorrect encoding by 36% compared to the previous releases of FineReader PDF. This allows FineReader PDF to reconstruct text encoding in approximately two out of three PDFs with incorrect encoding. Which, admittedly, is a pretty good result and an improvement in the right direction.
Edit PDFs in Thai language more easily and more effectively
Thai language has a complicated script, and editing of PDFs in this language can be a rather difficult task, sometimes resulting with upper- and under-line parts of the characters misaligned. With Release 3, this problem has been addressed, and now most PDFs in Thai can be edited as effectively and easily as the PDFs in other supported languages.
Control background processes performance
When you open an image-based PDF document in PDF Editor or start editing a PDF, background recognition and preparing the PDF for editing are crucial processes done by FineReader PDF to help you to get access to the content of your PDF. FineReader PDF 16 recognizes the content very efficiently, utilizing most of the computer resources to get it done fast. However, being OCR-based processes, they are resource-demanding, and in some cases, you may want to limit the amount of processing power allocated to them.
Starting from the Release 3, you can customize this with the “Number of processor cores used for OCR” setting. Previously, it was affecting only document conversion in OCR Editor, but now it simultaneously limits the number of processor cores used for background processes in PDF Editor, too. The default setting, however, is still to use all but one available processor cores to make sure your FineReader PDF operates as fast as possible.
Converting PDFs and document images: Smarter PDF conversion, new feature, and UI improvements
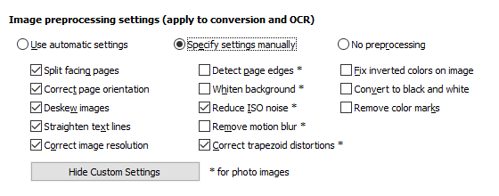
Control image preprocessing settings with more flexibility
Control over the image preprocessing tools applied to page images for conversion has been enhanced with another variant of the settings: “No preprocessing”. This does exactly what it says—makes sure that the original images aren’t altered in any way during conversion. Whenever you may need that, it’s now available with just one click in the settings on the “No preprocessing” option.

And it's as easy to return to your regular preprocessing mode and settings to continue working with other documents. Simply switch back to one of the other modes—all settings you had set before are preserved there.
Assign styles “Heading” role for automatic creation of bookmarks when converting to PDFs
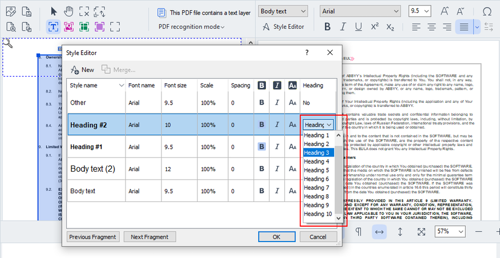
Previously, only headings automatically detected by FineReader PDF when converting a document in the OCR Editor could be used to automatically create bookmarks when saving the document to PDF. User-defined styles, even if named “Heading”, could not create bookmarks in PDF.
Now, starting from Release 3, every style, including those created by users, can be assigned with a role “Heading” of various levels (up to ten levels are supported). If assigned, all texts with such style will create a bookmark of the corresponding level when saving a converted document to PDF using the option “Create bookmarks from headings” on.
Convert and compare PDFs more easily
A new default OCR mode, Pull&Recognize has been applied in PDF Editor, OCR Editor, Compare Documents, and Hot Folder. It’s now there under the same default option “Automatically choose between OCR and text from PDF” in the PDF recognition mode setting, so you don’t have to change any settings to have the new mode work for you.
When converting PDFs or preparing them for comparison, the new mode ensures correct digital text extraction even if the document language or languages are not set correctly by the user. From PDFs with mixed content (when some of the text is digital, some is in images), the new mode can extract digital text and recognize the texts in the images, providing better overall quality of conversion.
Delete blank pages when converting documents
In addition to PDF Editor (see above), detecting and deleting blank pages from a document is also available when converting documents in OCR Editor and Hot Folder.
In OCR Editor, you can find the option in the main menu: Edit → Delete Blank Pages, or use a keyboard shortcut Ctrl+Alt+Backspace. It works the same way as in PDF Editor: you will get a window with a preview of all blank pages found in the document to review and confirm deleting them.
In Hot Folder, deleting of blank pages is done without user confirmation. When you set a task, there’s an “Automatically delete blank pages” option in the “Process document” section. Additionally, you can choose to save deleted pages to a selected folder in order to inspect them later.
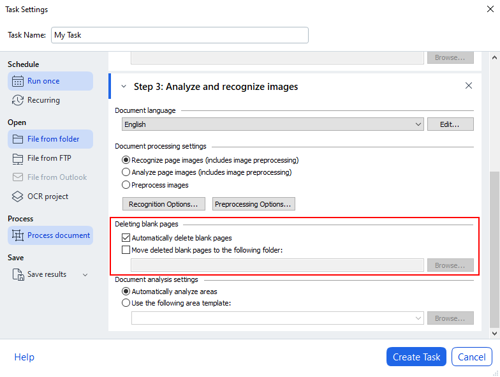
By the way, notice the updated user interface of Hot Folder–it’s now harmonized with the new FineReader PDF 16 style.
Other updates
Among other updates made in Release 3 of FineReader PDF 16, there are new End-User License Agreements and a comprehensive number of bugs have been fixed; you can check the Release Notes to learn about the most noticeable ones.
Discontinued feature
PDF X-Change virtual printer component has been removed from FineReader PDF 16. Some features, associated with it, were affected. For more details, please see this article in the ABBYY Help Center.
How to learn what is new in every FineReader PDF release
Follow our blog—subscribe by filling out the form on the right (or below if you’re reading this from your mobile device). Also, at any time you can consult the FineReader PDF Release Notes, where the full list of improvements and major bug fixes for every release are documented. To identify the release version you have, use the part #, which you can find in the product by going to the “Help” → "About" menu.
Remember to update your FineReader PDF 16 to Release 3: click Help → Check for Updates... in the main menu.
Stay tuned for more news and interesting articles!


